
In addition to metric data, Cloud Observability’s Unified Query Language (UQL) can be used to retrieve and process your span data. This guide will help you understand how you can use UQL to operate on span data.
For more details on specific stages, see the UQL Reference. We also have a UQL Cheatsheet to help you build queries.
Why use UQL to query span data?
Cloud Observability enables querying of spans time series data via the query builder and UQL. UQL enables a more flexible and extensible query experience, allowing you to write more complex filter expressions on attribute keys, combine spans time series in various ways, query numerical attributes on spans and calculate custom latency percentiles.
Querying span data via UQL
Fetch/Data generation
All spans queries must start with a fetch, or data generation, statement. Just like you would start a metrics query with the keyword metrics and then specify a metric name, with spans queries you start the query with the keyword spans, and then specify a fetch type:
| Fetch Type | Example | Description |
|---|---|---|
| count | spans count |
Produces a delta float counting the number of spans, adjusted to account for sampling |
| count_unadjusted | spans count_unadjusted |
Produces a delta float counting the raw number of retained spans |
| latency | spans latency |
Produces a delta distribution for the latency of spans |
| custom-numeric-attribute | spans request.size |
Produces a delta distribution of the values of custom-numeric-attribute |
The fetch type determines what sort of spans time series data is returned for your query.
The most basic spans UQL query you can write is spans count | delta | group_by [], sum. This returns to you the count of spans across all services reporting to Cloud Observability.
The ability to query a distribution based on a custom attribute of spans is a powerful feature of UQL. This means that as long as an attribute is float or integer valued, a distribution can be created based on the values of the attribute.
Alignment
Like UQL metrics queries, an alignment stage is required for spans queries. If you are issuing a spans count or spans count_unadjusted query, you can use the delta, rate, and reduce aligners. You can provide an input window and output period to any aligner.
The total count of spans sent by the warehouse service
1
2
3
4
spans count
| delta
| filter service = "warehouse"
| group_by [], sum
The count of spans sent by the warehouse service retained after sampling
1
2
3
4
spans count_unadjusted
| delta
| filter service = "warehouse"
| group_by [], sum
The rate (ops/s) of the database-update operation in the warehouse service, over a rolling 10m window
1
2
3
4
spans count
| rate 10m
| filter service = "warehouse" && operation = "database-update"
| group_by [], sum
If you are issuing a spans latency query, you must use a delta aligner. This is because a these queries produce a distribution of spans latency.
The p99 latency of the database-update operation in the warehouse service
1
2
3
4
5
spans latency
| delta
| filter service = "warehouse" && operation = "database-update"
| group_by [], sum
| point percentile(value, 99)
Filter by attributes
You can filter your spans queries by any attribute on a span, using &&, ||, !=, ==, =~ and !~ boolean operators.
The rate (ops/s) of requests to the android and iOS service made by customer sweetpines
1
2
3
4
spans count
| rate
| filter (service = "android" || service = "iOS") && customer = "sweetpines"
| group_by [], sum
The p50 latency for writes to database services
1
2
3
4
5
spans latency
| delta
| filter (service = "transaction-db" && operation = "INSERT") || (service = "inventory-db" && operation = "UPDATE")
| group_by [], sum
| point percentile(value, 50)
The above query is possible in UQL because of the flexibility in constructing boolean expressions.
Filter by span latency
You can filter spans by their derived latency. Latency filter supports numerical comparison operators like >, >=, <, <=, !=, and == with a duration value.
A duration value includes duration and the unit of time. For example, the query below counts the number of spans by service that exceed 10 seconds by using 10s:
1
2
3
4
spans count
| filter latency > 10s
| delta
| group_by [service.name], sum
Duration values have two constraints for latency filters:
- Fractional durations are not supported.
1.5swould need to be re-written as1500ms. - The value, when converted to seconds, should have at most two significant figures.
101mswould need to be re-written as100msor110ms.
Supported units for latency filters include:
usorμsfor microsecondsmsfor millisecondssfor seconds
Latency filters also support hours h, minutes m, and d days. But only if value represents 2 significant digits of a power 10 in seconds. 60m is supported since it’s equal to 3600s and is 2 significant figures. Yet, 61m is not supported since it’s equal to 3660s which is 3 significant figures.
Latency filters are not available for alerts.
Aggregation / Group By
Just as in metrics UQL queries, group_by combines rows with the same timestamps and the same values for the listed attribute keys using the provided reducer.
Unlike in metrics UQL queries, an aggregation (group_by) stage is required for spans queries. This is due to the cardinality constraints around returning a time series for every attribute combination for spans - the data is just far easier to read and interpret when there is a group_by stage.
To aggregate across all attributes and have your query produce a single time series, provide an empty field list ([]) as a group_by argument: group_by [], sum.
The following query produces a single time series:
The total count of spans, summed up across every attribute key
1
spans count | delta | group_by [], sum
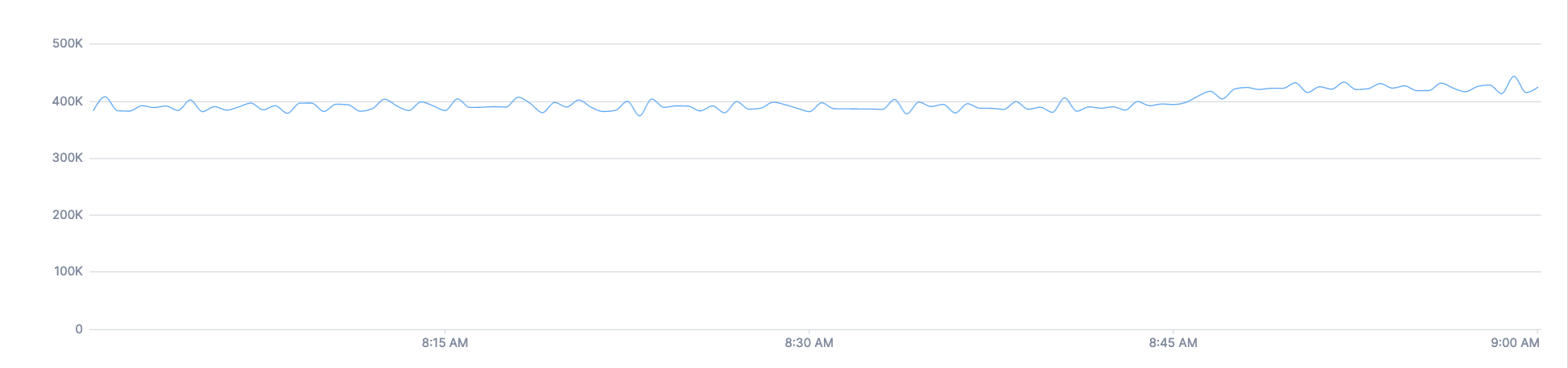
This query produces a time series for every service reporting to Cloud Observability:
The count of spans, summed up by service
1
spans count | delta | group_by [service], sum
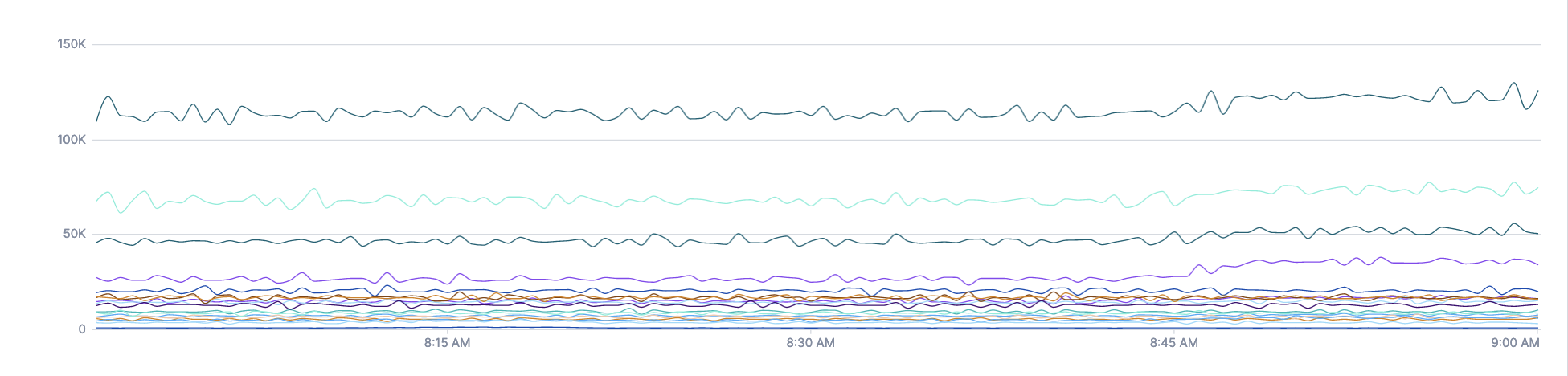
Point and Join stages
You can use a join expression to combine two or more spans time series. Join expressions have the same syntax for spans queries as they do for metrics.
Error percentage for service android
1
2
3
4
(
spans count | delta | filter error == true && service == android | group_by [], sum;
spans count | delta | filter service == android | group_by [], sum
) | join left/right * 100
To transform a time series point by point, you can use a point stage with any number of arithmetic operators.
The 99th percentile latency for the iOS service
1
spans latency | delta | filter service = iOS | group_by [], sum | point percentile(value, 99)
Approximate total bytes received by the warehouse-db service
1
spans client-request-size-bytes | delta | point dist_sum(value) | filter service = warehouse-db | group_by [], sum
Query Cloud Observability-specific attributes
Cloud Observability has attributes you can use to query for specific spans or traces.
-
Search for a specific span ID
lightstep.span_idExample: Return span with the ID
1a2b902a0ff1a9e3You can find the span ID in the Trace view
-
Search for spans from a specific trace
lightstep.trace_idExample: Return spans that are not included in a trace with the ID
bd1285b6af0acd8dYou can find the trace ID in the Trace view
-
Search for spans sent by a specific tracer
lightstep.tracer_idExample: Return spans from the tracer with the ID
cebd0875ab -
Return a distribution of bytes
lightstep.bytesizeExample: Return the 99th percentile of bytes sent to Cloud Observability by service
spans lightstep.bytesize | delta | group_by [service], sum | point percentile(value,99) -
Search for spans that have no parent
lightstep.is_root_span:
See also
Get started with distributions in UQL
Updated Jan 4, 2023